我们在项目中使用Redis,肯定不会是单点部署Redis服务的。因为,单点部署一旦宕机,就不可用了。为了实现高可用,通常的做法是,将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务。Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
主从模式中Redis部署了多台机器,有负责读写操作主节点和只负责读操作从节点,从节点的数据来自主节点,实现原理就是主从复制机制。主从复制包括全量复制,增量复制两种。一般当slave第一次启动连接master,或者认为是第一次连接,就采用全量复制,全量复制流程如下:
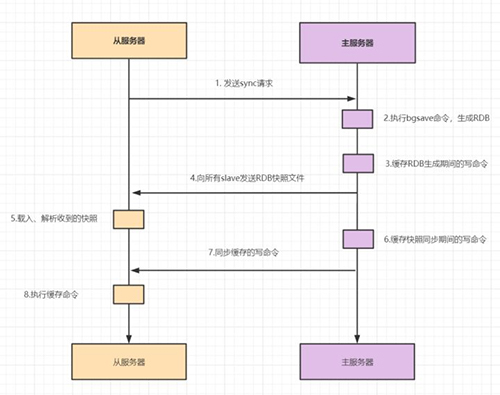
1.slave发送sync命令到master。
2.master接收到SYNC命令后,执行bgsave命令,生成RDB全量文件。
3.master使用缓冲区,记录RDB快照生成期间的所有写命令。
4.master执行完bgsave后,向所有slave发送RDB快照文件。
5.slave收到RDB快照文件后,载入、解析收到的快照。
6.master使用缓冲区,记录RDB同步期间生成的所有写的命令。
7.master快照发送完毕后,开始向slave发送缓冲区中的写命令;
8.salve接受命令请求,并执行来自master缓冲区的写命令
redis2.8版本之后,已经使用psync来替代sync,因为sync命令非常消耗系统资源,psync的效率更高。
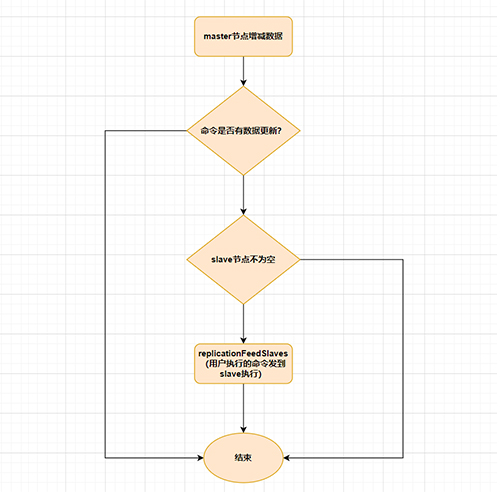
slave与master全量同步之后,master上的数据,如果再次发生更新,就会触发增量复制。
当master节点发生数据增减时,就会触发replicationFeedSalves()函数,接下来在 Master节点上调用的每一个命令会使用replicationFeedSlaves()来同步到Slave节点。执行此函数之前呢,master节点会判断用户执行的命令是否有数据更新,如果有数据更新的话,并且slave节点不为空,就会执行此函数。这个函数作用就是:把用户执行的命令发送到所有的slave节点,让slave节点执行。流程如下:
Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务:
1)监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
2)提醒(Notification):当被监控的某个 Redis出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
3)自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用Master代替失效Master。
监控主数据库和从数据库是否正常运行。
主数据库出现故障时,可以自动将从数据库转换为主数据库,实现自动切换。
当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
其实整个过程只需要一个哨兵节点来完成,首先使用Raft算法(选举算法)实现选举机制,选出一个哨兵节点来完成转移和通知
1)哨兵集群至少要 3 个节点,来确保自己的健壮性
2)redis主从 + sentinel的架构,是不会保证数据的零丢失的,它是为了保证redis集群的高可用.
会有,主要考虑下面两种情况。
1)主从异步复制导致的数据丢失:redis master 和slave 数据复制是异步的,这样就有可能会出现部分数据还没有复制到slave中,master就挂掉了,那么这部分的数据就会丢失了
2)脑裂导致的数据丢失:脑裂其实就是网络分区导致的现象,比如,我们的master机器网络突然不正常了发生了网络分区,和其他的slave机器不能正常通信了,其实master并没有挂还活着好好的呢,但是哨兵可不是吃闲饭的啊,它会认为master挂掉了啊,那么问题来了,client可能还在继续写master的呀,还没来得及更新到新的master呢,那这部分数据就会丢失。
如果一个master被认为宕机了,而且majority多数哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个slave来,主要通过下面几个步骤
1)slave跟master断开连接的时长(断开时间越短优先级越高)
2)slave优先级(在配置文件中的配置,slave priority越低,优先级就越高。)
3)复制offset(哪个slave复制了越多的数据,offset越靠后,优先级就越高。)
4)run id(如果上面两个条件都相同,那么选择一个run id比较小的那个slave)
redis从3.0开始支持集群功能。redis集群采用无中心节点方式实现,无需proxy代理,客户端直接与redis集群的每个节点连接,根据同样的hash算法计算出key对应的slot,然后直接在slot对应的redis节点上执行命令。在redis看来,响应时间是最苛刻的条件,增加一层带来的开销是redis不能接受的。因此,redis实现了客户端对节点的直接访问,为了去中心化,节点之间通过gossip协议交换互相的状态,以及探测新加入的节点信息。redis集群支持动态加入节点,动态迁移slot,以及自动故障转移。

官方微信

官方抖音










 京公网安备 11030102010736号
京公网安备 11030102010736号