专注Java教育14年
全国咨询/投诉热线:400-8080-105
更新时间:2022-09-26 10:07:19 来源:动力节点 浏览1902次

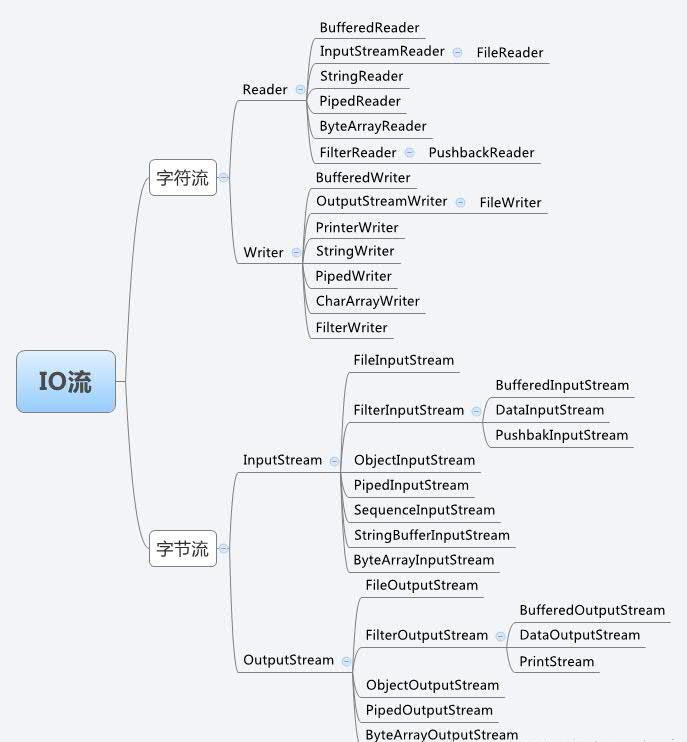
IO 几种常见的流:

I/O 流原理功能
Input/Output:输入输出机制
输入机制:允许java程序从外部设备(磁盘、光盘、网络等)获取数据。
输出机制:保留java程序中的数据,输出到外部设备(磁盘、CD等)。
以不同的方式,您可以进行分类。
1.按功能划分:
输入流:只能从中读取数据,而不是向其写入数据。
输出流:只能写入数据,不能从中读取数据。
2.按处理单元划分
字节流和字符流的操作方式基本相同。操作的数据单位不同
字节流:操作为 8 Bytes of bits InputStream/OutputStream 作为字节流的基类
字符流:操作为 16 个字符 Reader/Writer 作为字符流的基类
关于字节流和字符流的区别?
当读取一个字节流时,读取一个字节并返回一个字节。字符流使用字节流读取一个或多个字节(中文对应字节为两个,UTF-8码表中有三个)时,首先查看指定的
编码表,将找到的字符返回给。
字节流可以处理所有类型的数据,例如图片、mp3、视频等。字符流只能处理字符数据。
字节流和输入流均以 InputStream 结尾,字节输出流均以 OutputStream 结尾。在 InputStream 或者 OutputStream 前面代表这个流的功能。
字符流输入流以Reader结尾,字符输出流以Writer结尾,同一字符流前面的字符代表流的功能。
其实字节流本身在操作的时候不会用到缓冲区,直接操作的是文件本身,但是字符流在操作的时候会用到缓冲区,文件是通过缓冲区来操作的。
用字节流还是字符流比较好?
答:字节流,因为硬盘上的所有文件都是以字节的形式传输或保存的,包括图片等。但是字符流只是在内存中形成的,所以在实际开发中,字节流的使用更为广泛。
摘要:如果是处理纯文本数据,我们必须优先考虑字符流,另外,它们都使用字节流。
节点流:可以直接从/读取到外部设备/写入数据的流,这称为节点流,节点流也称为低级流。
处理流程:连接和封装现有流程,扩展原有的读/写功能。处理流程也称为高级流程。
Java 的 io 包包括 40 多个流,它们都有密切的联系和使用规则,这些流都来自 4 个抽象基类。
InputStream/Reader:所有输入流的基类,前者为字节输入流,后者为字符输入流。
OutputStream/Writer:基本上都是所有的输出流,前者是字节输出流,后者是字符输出流。
File 类起源:File Class 弥补了 IO 流的不足,IO 只能操作数据,但不能对文件的信息进行操作,操作文件必须使用 File 类(Java File类概述)。
功能 :
一个。您可以将文件或文件夹拆分为程序中的对象。
湾。方便操作文件或文件夹中的属性信息。
C。File Class 通常通过构造函数作为参数传递给流的对象。
File类的常用方法:
1.构造方法:
File(String pathname):这种构造可以将现有或不存在的文件或文件夹封装成 File 的对象,pathname 文件的路径。
File(File parent,String child):parent by child 文件的路径。
(1)文件路径
文件 f6 = 新文件(“c:\java”,“jre7”);
//file 的 toString 方法被覆盖,无论打包地址打印
//'/' 和 '\' 所有目录分隔符,在其他系统中,目录分隔符可以改变,这样写不利于跨平台操作 // 最好使用 File分隔符 Segmentation 中提供的字段。
(2)创建文件相关功能:
createNewFile():创建相关文件。并返回布尔值
createTemFile(): 在默认临时文件目录下创建一个空文件,程序运行后不存在。
mkdirs():创建目录,如果你写的目录的父目录不存在。他会帮你创作。
(3)删除文件相关功能:
delete():删除空目录或文件(ps只能是空目录)
deleteOnExit():虚拟机终止时删除文件。
(4)裁判:
exists() :判断文件或文件夹是否存在。
canExecute() :判断文件是否可执行,跟操作系统有关。
canRead() : 判断文件是否可读
canWrite() : 判断文件是否可写
equals(Object obj) : 测试抽象路径名是否等于给定的对象。
isAbsolute() :测试这个抽象路径名是否是绝对路径名。
isDirectory() :判断文件对象代表一个文件夹。
isFile() : 判断文件对象代表一个文件
isHidden() : 判断文件对象是否为隐藏文件
(5)获取文件对象属性信息的方法:
getAbsoluteFile() :返回这个抽象路径名的绝对路径名形式。
getAbsolutePath() :返回这个抽象路径名的绝对路径名字符串。
getCanonicalFile() :返回这个抽象路径名的规范形式。
getCanonicalPath() :返回此抽象路径名的规范路径名字符串。
getPath() :将此抽象路径名转换为路径名字符串。
getName() :返回此抽象路径名表示的文件或目录的名称。
getParent() :返回此抽象路径名的父目录的路径名字符串;如果没有为此路径名指定父目录,则返回null。
getParentFile() :返回此抽象路径名的父目录的抽象路径名;如果没有为此路径名指定父目录,则返回null。
getTotalSpace() :返回指定路径的总空间中的字节数
getFreeSpace() :返回此抽象路径名指定的分区中未分配的字节数。
getUsableSpace() :返回此抽象路径名指定的分区上此虚拟机可用的字节数。
renameTo(File dest) :重命名此抽象路径名表示的文件。剪切
(6)如何设置文件信息:
setExecutable(boolean executable) :设置文件可执行方法
setLastModified(long time) :设置此抽象路径名指定的文件或目录的最后修改时间。
setReadable(boolean readable) : 设置文件是否可读
setReadOnly() : 设置文件是否只读
setWritable(boolean writable) : 设置文件是否可写
(7)如何获取文件的一般信息:
lastModified() :获取文件的最后修改时间
length() :返回这个抽象路径名所代表的文件的长度。
(8)如何操作文件夹
list():将文件夹中包含的目录和文件存储到字符串数组中。
listFiles():列出文件夹中包含的目录和文件,存放在 File 数组中。
listRoots():列出可用的文件系统根目录。
(9)文件过滤器: FileFilter
布尔接受(文件路径名);该接口的一个实例可以用来传递给 File 类的 listFiles(FileFilter) 方法,用来返回满足过滤器要求的子
文件 File [] listFiles(FileFilter filter)
1. 节点流
字节数组流(内存流)
ByteArrayInputStream
ByteArrayOutputStream
因为内存输出流中有新的方法,不要使用多态,不能让父类的引用指向那样的东西。
效果:循环中可以将所有数据存储在一个统一的容器中,然后在循环结束时,可以一起取出容器中的所有内容。
注意事项:
内存流属于内存中的资源,所以不要过度,如果太大,会出现内存溢出错误。
2. 缓冲流量
缓冲字节流
BufferedInputStream
BufferedOutputStream
缓冲字符流
BufferedReader
BufferedWriter
处理流包含节点流,节点流决定与之通信的外部设备,处理流增加其功能。
缓冲流的好处:
缓冲流里面包含一个缓冲区,默认8kb,每次程序调用read方法实际上都是从缓冲区中读取内容,如果读取失败
则说明缓冲区中没有内容,然后从数据源,然后将尽可能多的字节读取并放入缓冲区,
最后将缓冲区的内容,全部返回给程序。
从缓冲区读取数据比直接从数据源读取数据要快,效率更高,性能更好。
简而言之:
没有缓存,那么每读一次,就会发送一次IO操作;有一个缓冲区,第一次读的时候,我会读x个字节到缓存中,
然后read会从缓存中读取,当读到缓冲区结束时,会再读x个字节到缓存中。
流处理数据的方法与节点流处理方法基本相同。
3. 转化流量
转换流功能:将字节流转换为字符流,可以解决编码集和解码集造成的乱码问题。
输入流读取器:
输出流编写器:
code : character —– 编码字符集 ——–》 二进制
decode : 二进制——解码字符集 ———》 字符
在处理文件时,如果文件的字符格式与编译器的不同,就会出现乱七八糟的情况。比如文件字符格式GBK,
而编译器是UTF-8格式,那么问题就来了。
乱码问题的原因:
(1)编码和解码字符集不一致导致乱码
(2)丢失字节,丢失长度
大多数情况下,出现乱码问题的原因是汉字,因为汉字在不同的字符码中占用不同的字节,但都占用多个字节。
而英文字母则没有这个问题,因为英文字母在所有字符编码中占据一个字节。
InputStreamReader : Transform the input stream –》 Convert byte input stream to character input stream
效果:为了防止文件使用字符输入流处理出现乱码问题。
4.数据处理流程
DataOutputStream
DataInputStream
特性:可以保存数据本身,并且可以保存数据类型(基本数据类型+String)
5.序列化流程
将对象转化为字节序列的过程,就是对象序列化的过程。
将字节序列恢复到对象的过程称为对象反序列化。
效果:保持对象(引用数据类型data)类型+数据。
序列化流程: 输出流 ObjectOutputStream writeObject()
反序列化流:输入流 ObjectInputStream readObject()
注意事项:
先序列化,再反序列化,并且反序列化的顺序必须和序列化的顺序一致。
并非所有对象都可以序列化。只有当 Serializable 接口类的对象才能被序列化。
并非对象中的所有属性都可以序列化。
对象序列化的主要目的:
将对象转换为字节序列,保存到硬盘,持久化存储,通常保存为文件。
在网络上传递的是对象的字节序列
对象序列化步骤:
创建对象输出流,其他输出节点流可以包含在构造方法中,如文件输出流。
将对象通过 writeObject 来写入。
对象反序列化步骤:
创建对象输入流,构造方法中可以包含其他输入节点流,如文件输入流
通过 readObject() 方法读取对象。
serialVersionUID : 序列化版本 id
效果:字面意思,就是序列号。一切都实现了 Serializable 接口的类,会有一个默认的静态序列化ID。
不同版本之间的类,可以解决序列化兼容性的问题,如果一个对象在之前的版本中保存在一个文件中,那么版本升级后,如果序列化id一致,我们可以认为文件中的对象还是对象这种。
如果类不希望不同版本之间兼容,但是我们也希望类的对象是有序的,那么在不同的版本id中使用不同的序列化。
瞬态:当类中有不想被序列化的属性时,所以使用这个修饰符来修改。
以上就是关于“Java中的io流知识总结”介绍,对于初学者来说,可以看看本站的Java IO流的分类,对IO流有一个初步的认识,这样在以后的学习中会更加顺畅。
 Java实验班
Java实验班
0基础 0学费 15天面授
 Java就业班
Java就业班
有基础 直达就业
 Java夜校直播班
Java夜校直播班
业余时间 高薪转行
 Java在职加薪班
Java在职加薪班
工作1~3年,加薪神器
 Java架构师班
Java架构师班
工作3~5年,晋升架构
提交申请后,顾问老师会电话与您沟通安排学习

官方微信

官方抖音

















 京公网安备 11030102010736号
京公网安备 11030102010736号