 二叉树面试题
二叉树面试题
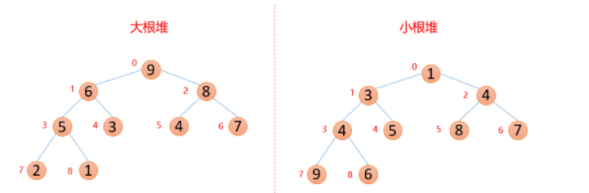
堆结构如下图,堆的实际结构是数组,但是我们在分析它的时候用的是有特殊标准的完全二叉树来分析。也就是说数组是堆的实际物理结构而完全二叉树是我们便于分析的逻辑结构。堆有两种:大根堆和小根堆。每个节点的值都大于其左孩子和右孩子节点的值,称为大根堆。每个节点的值都小于其左孩子和右孩子节点的值,称为小根堆。
上面的结构映射成数组就变成了下面这个样子

1.首先堆的大小是提前知道的,根节点的位置上存储的数据总是在数组的第一个元素。
2.假设一个非根节点所存储的数据的索引为i,那么它的父节点存储的数据所对应的索引就为[(i-1)/2]
3.假设一个节点所存储的数据的索引为i,那么它的孩子(如果有)所存储的数据分别所对应的索引为:左孩子是[2*i+1],右孩子是[2*i+2]
第一步,将待排序的数组构造成一个大根堆,假设有下面这个数组:

具体思路:第一次保证0~0位置大根堆结构,第二次保证0~1位置大根堆结构,第三次保证0~2位置大根堆结构...直到保证0~n-1位置大根堆结构(每次新插入的数据都与其父节点进行比较,如果插入的数比父节点大,则与父节点交换。周而复始一直向上比较,直到小于等于父节点或者来到了根节点则终止)
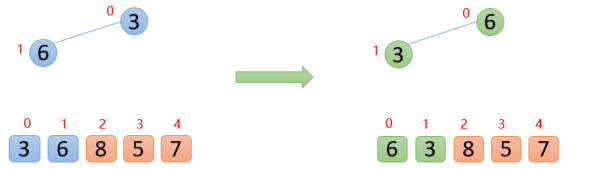
【1】插入6的时候,6大于他的父节点3,即arr(1)>arr(0),则交换;此时保证了0~1位置是大根堆结构,如下图:
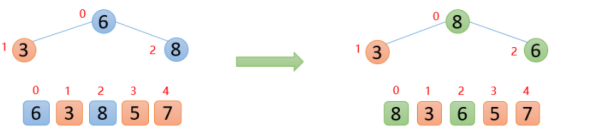
【2】插入8的时候,8大于其父节点6,即arr(2)>arr(0),则交换;此时,保证了0~2位置是大根堆结构,如下图
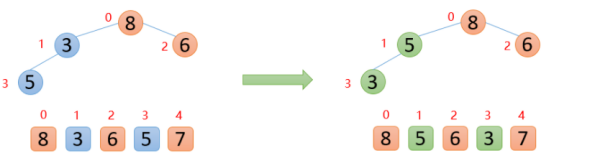
【3】插入5的时候,5大于其父节点3,则交换,交换之后,5又发现比8小,所以不交换;此时,保证了0~3位置大根堆结构,如下图
【4】插入7的时候,7大于其父节点5,则交换,交换之后,7又发现比8小,所以不交换;此时整个数组已经是大根堆结构
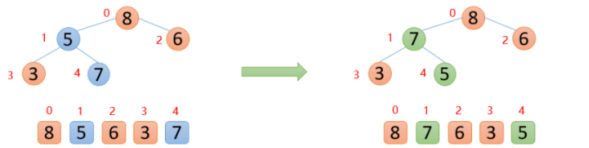
第二步,将根节点的数与末尾的数交换
【1】大根堆中整个数组的最大值就是堆结构的父节点,接下来将根节点的数8与末尾的数5交换

第三步,将剩余的n-1个数再构造成大根堆
如上图所示,此时最大数8已经来到末尾,让堆的有效大小减1,后面拿顶端的数与其左右孩子较大的数进行比较,如果顶端的数大于其左右孩子较大的数,则停止,如果顶端的数小于其左右孩子较大的数,则交换;周而复始一直向下比较,直到大于左右孩子较大的数或者没有孩子节点则终止。
下图中,5的左右孩子中,左孩子7比右孩子6大,则5与7进行比较,发现5<7,则交换;交换后,发现5已经大于他的左孩子,说明剩余的数已经构成大根堆,

第四步,再将第二步和第三步反复执行,便能得到有序数组
首先遍历该数组,假设某个数处于index位置,每次都让index位置和父节点位置的数进行比较,如果大于父节点的值就交换位置,....周而复始,一直到不能往上为止。
for (int i = 0; i < arr.length; i++) { // O(N)
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
先将大根堆的头节点的数据与堆上的最后一个数交换位置后,把堆有效区的长度减1,再从头节点开始做向下的比较,每次都和左右孩子中较大值进行比较,如果父节点比最大孩子的值下就交换位置....周而复始,一直到不能往下为止。
// 某个数在index位置,能否往下移动
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下标
while (left < heapSize) { // 下方还有孩子的时候
// 两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
// 父和较大的孩子之间,谁的值大,把下标给largest
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
具体实现前面的问题,具体源代码实现如下:
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//第一步,将待排序的数组构造成一个大根堆
for (int i = 0; i < arr.length; i++) { // O(N)
heapInsert(arr, i); // O(logN)
}
int heapSize = arr.length;
//第二步,将根节点的数与末尾的数交换
swap(arr, 0, --heapSize);
while (heapSize > 0) { // O(N)
//第三步,将剩余的n-1个数再构造成大根堆
heapify(arr, 0, heapSize); // O(logN)
//第二步,将根节点的数与末尾的数交换
swap(arr, 0, --heapSize); // O(1)
}
}
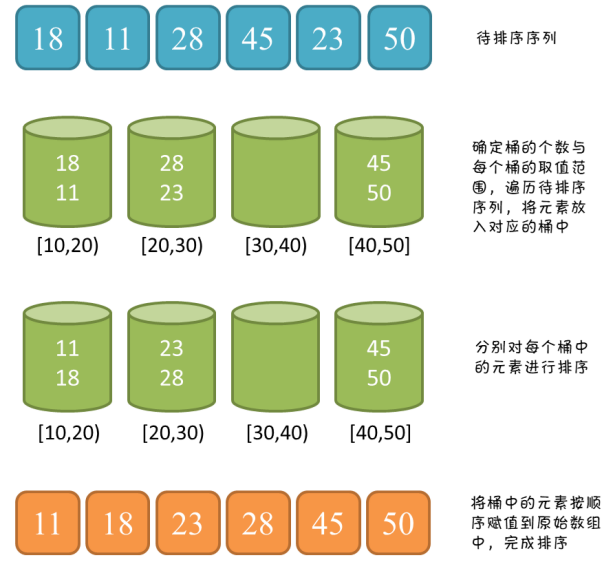
1)桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序),最后依次把各个桶中的记录列出来记得到有序序列。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,他不受到O(n log n)下限的影响。
2)算法图解
A. O(n^2)和O(1)
B. O(nlog(n))和O(1)
C. O(nlog(n))和O(n)
D. O(n^2)和O(n)
答案:B
解析:暂无解析

官方微信

官方抖音










 排序面试题
排序面试题 线性表面试题
线性表面试题 图算法面试题
图算法面试题 高频算法面试题
高频算法面试题 京公网安备 11030102010736号
京公网安备 11030102010736号